如何添加一个非rss网站?
1.概述
如果是技术人员想了解,那接着往下看,如果不是技术人员,可以直接加微信:fanyihui-support, 告诉我们您需要添加的网站以及您在翻一会的用户名,我们会直接添加好之后告诉您,您直接使用就可以了。
这个文档建议在电脑上看。
添加不提供rss的网站到”翻一会”,采用的是xpath方式,对xpath不了解的,又想仔细了解的,
可以看看 这个教程,这个教程大概半小时就看完了,挺简单的。
不想看也不影响,接着看下面给出的例子就可以了。
此处捡2个比较典型的例子讲解一下怎么用。
注意:添加非rss类的网站源推荐用电脑添加,不推荐用手机或者平板等屏幕小又不方便查xpath的设备
2.添加“推杯唤斩”这个播客
这个播客本身是提供rss,但是它提供的rss不标准,解析不了,后来还是直接从html网页抓取的。具体步骤如下:
2.1 打开“添加阅读源”
登录后点击主页右上角的“添加阅读源“就可以了,打开之后开始填空就行,下面就开始填空,每一个都会讲解怎么填。
2.2 网站地址
网站地址就是”https://talk.dyingfordrinking.com/“, 每个用户相同网站地址只能添加1个作为私人使用,要是公开之后,其他用户就不能再添加该网站了, 这个网站地址就是每一个阅读源中的“源网站”按钮所对应的超级链接。
2.3 是否单页
这是后期预留的,目前没有启用,此处选择否就行了。
2.4 是否公开
如果添加了该网站准备自用,就选否,如果是希望公开该网站,则选是, 选择公开的网站需要“翻一会”人工看过之后才能公开。
2.5 网站源地址
这个就是需要抓取网页的内容的地址了,一般html页面和前面的“网站地址”是一样的, 也就是“https://talk.dyingfordrinking.com/“ 。
2.6 网站源类型
由于我们直接通过网页抓取内容,因此选择”html”。
2.7 条目entry title的xpath css
这个就是最终想展示的每一条信息的标题的xpath,我们此处填”//h3”,具体是这样找到这个值的, 首先用火狐浏览器,当然google浏览器也可以, 打开“https://talk.dyingfordrinking.com/” 这个网站。
然后在网站上点击右键,选择“检查元素”,然后选择“查看器”,这时候您在查 看器下面的代码上面移动鼠标,会发现有时候鼠标停的时候,上面网页显示的整个网页底色都加深了,具体见图1。
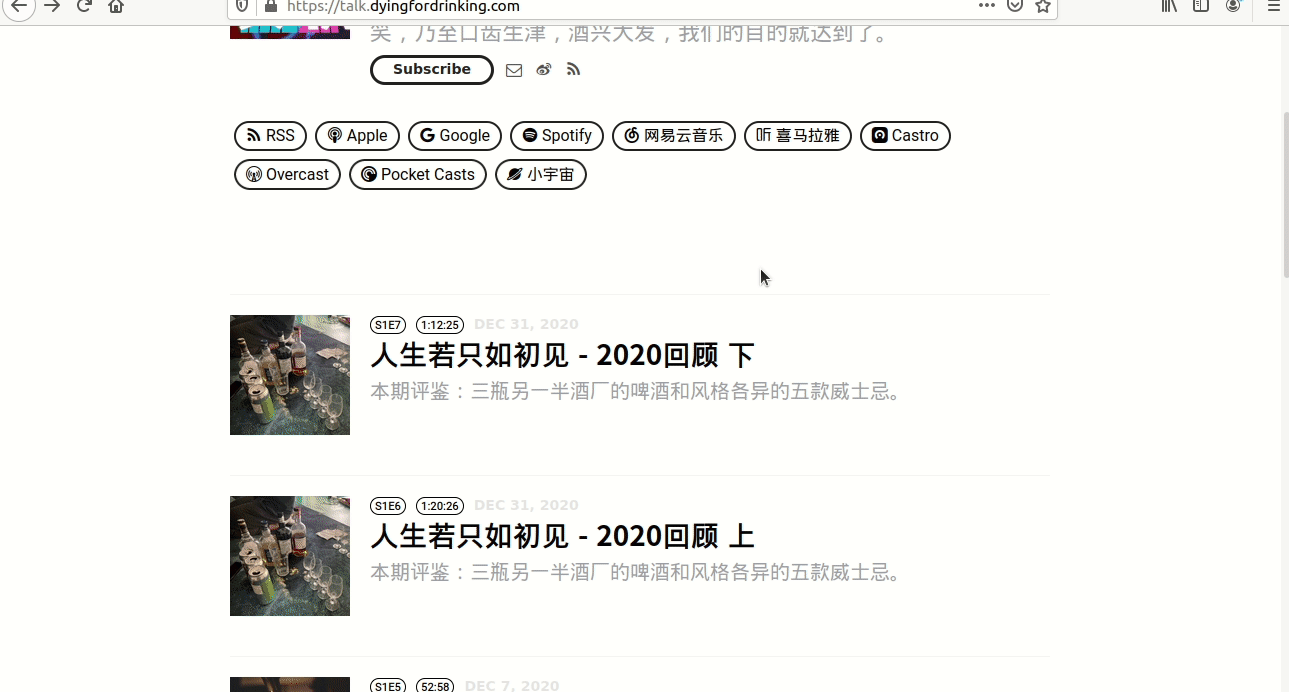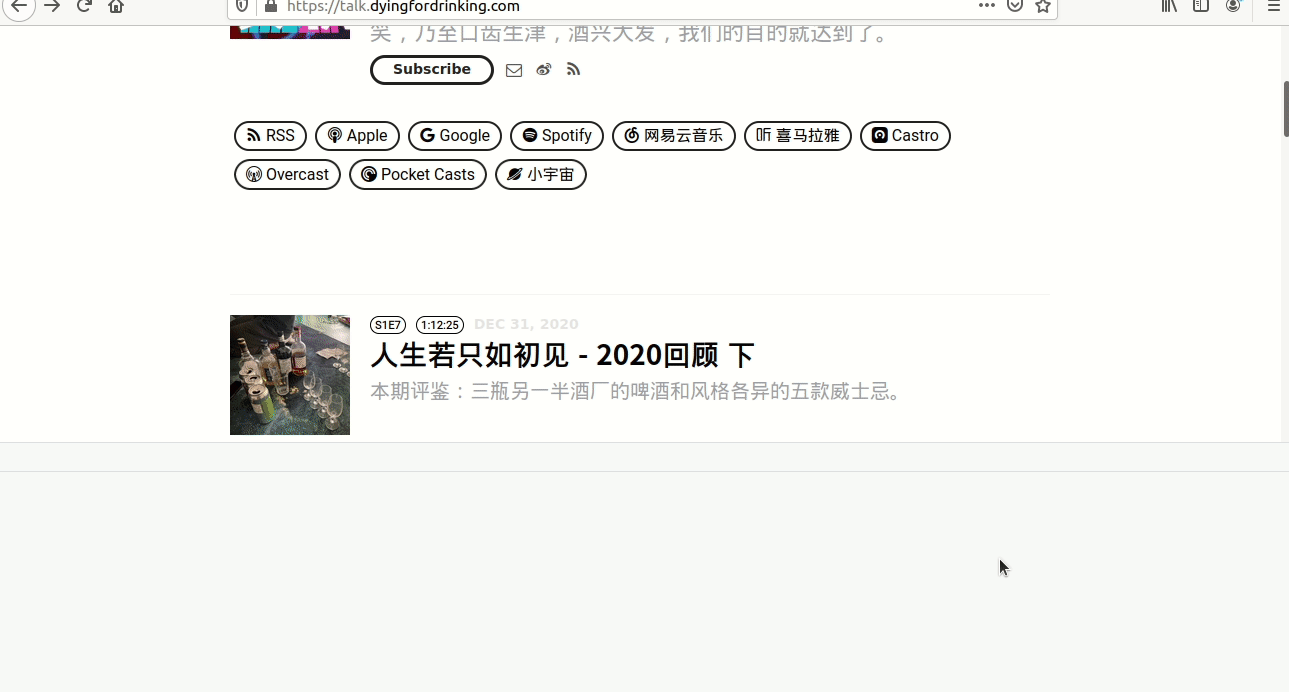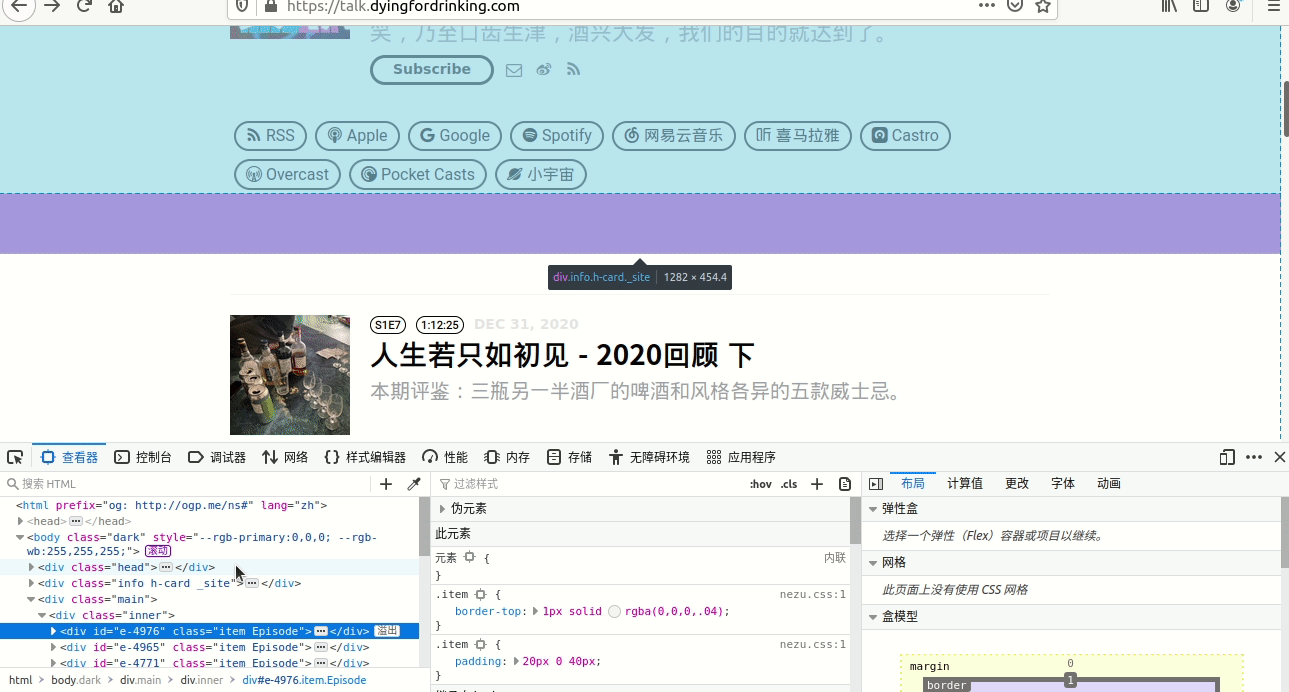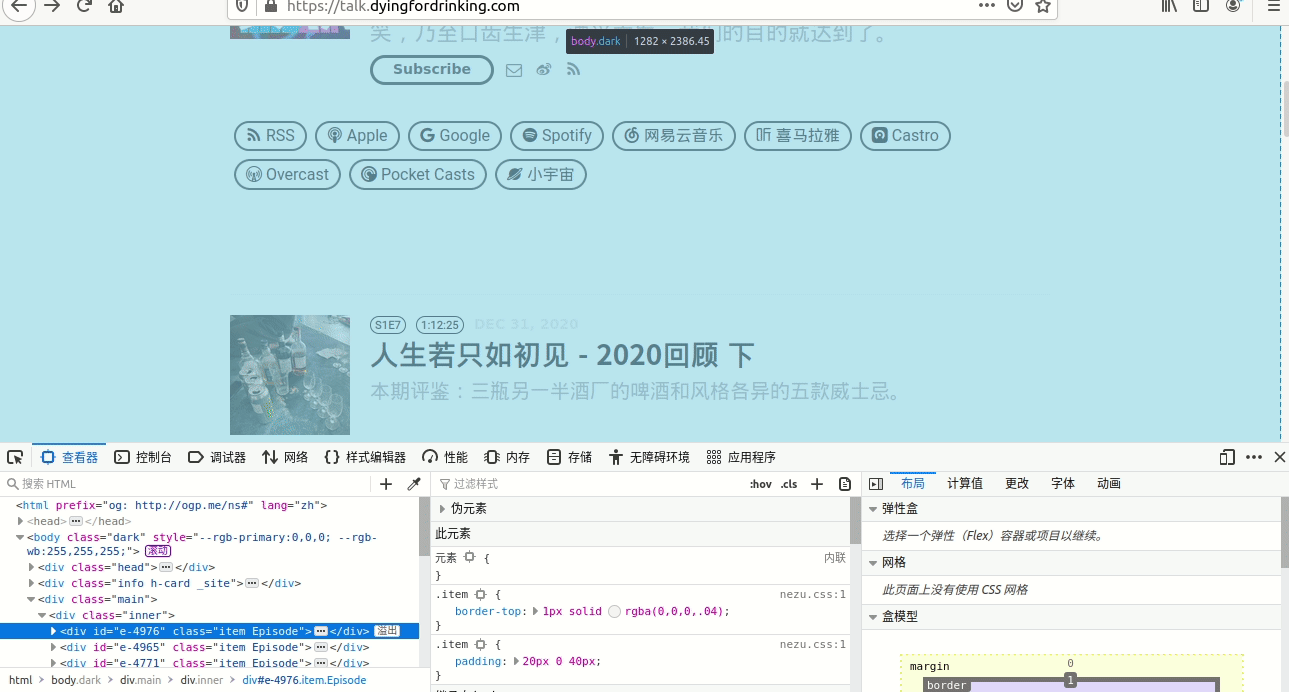
图1
上面说的鼠标一动,网页颜色就加深,证明鼠标所指的位置的源代码就是生成网页对应内容的源代码。
明白这点之后,再看我们想添加的内容,主要就是“人生若只如初见 - 2020回顾 下”、 “人生若只如初见 - 2020回顾 上”这些标题,那我们就挪动鼠标,找到对应的只让标题底色加深的地方, 然后右键->复制->xpath,然后将这个复制的值粘贴到随便哪个文本编辑器里面, 多选几个标题,都把对应的xpath都复制到同一个文本编辑器中,方便找到规律,具体操作见图2。
图2
仔细看图2截图过程,我们提取了两个标题的xpath,他们唯一的区别就是截图中用鼠标选过的2、3, 也就是“/html/body/div[3]/div/div[2]/a[2]/h3”和 “/html/body/div[3]/div/div[3]/a[2]/h3”,由于我们要提取所有的标题, 所以其实应该把标粗的[2]和[3]都去掉,也就是变成这个样子:“/html/body/div[3]/div/div/a[2]/h3”。
不过如果直接从html填起,其实还是比较麻烦,我们观察了下,其实可以改 为“//div[3]/div/div/a[2]/h3”,注意,此时打头的不是单斜杠“/”,而是双斜杠“//”, 除了从“html”开始是用单斜杠外,从其他任何一个元素开始都用双斜杠。
如果再观察观察,发现整个网页只有标题用的”h3”,那就可以直接用“//h3”,h3就是这么来的。
2.8 条目链接的entry link的xpath_css
这个和2.6是一样的,不过这次要找的是前面标题对应的超级链接,2.6和2.7必须要有,不然就不 能添加该网站。选择过程见图3。
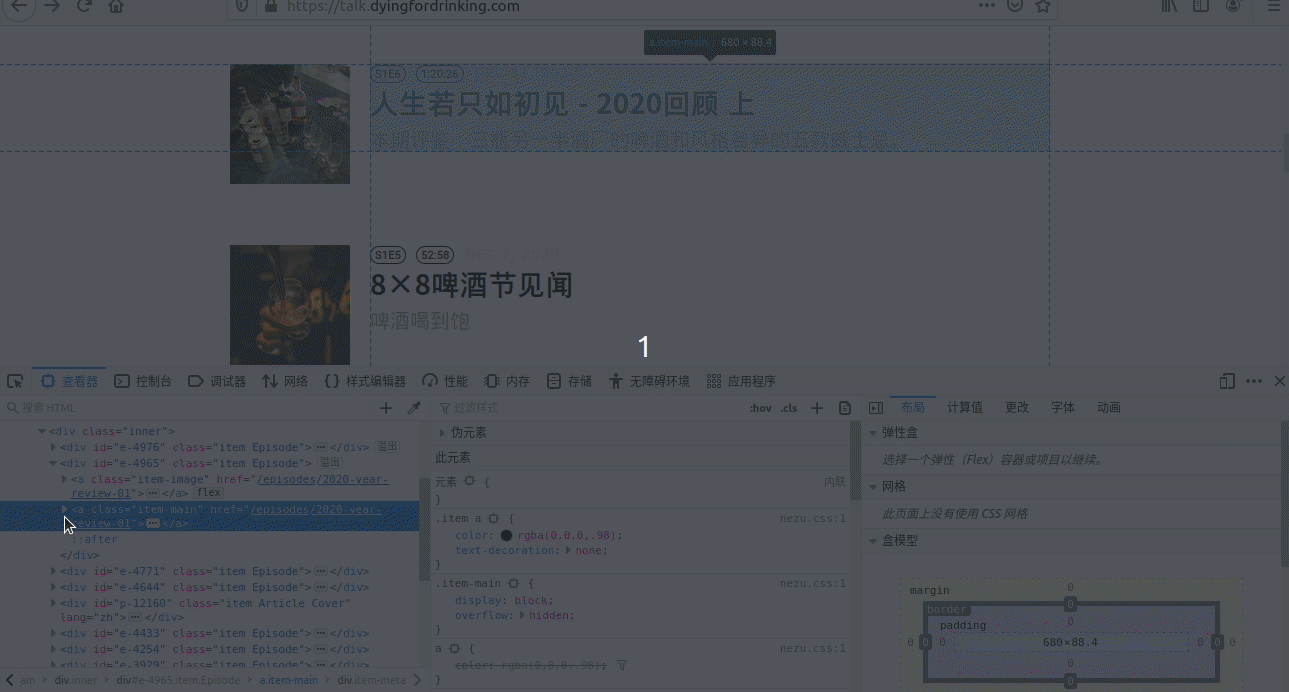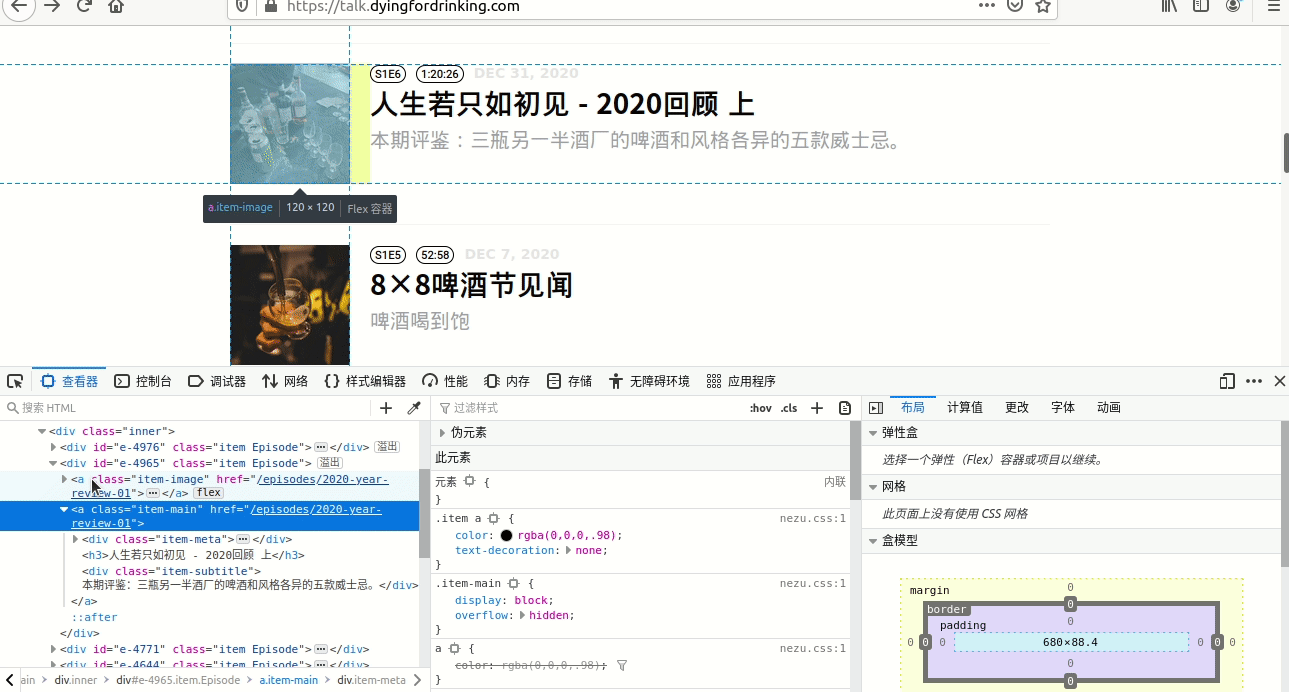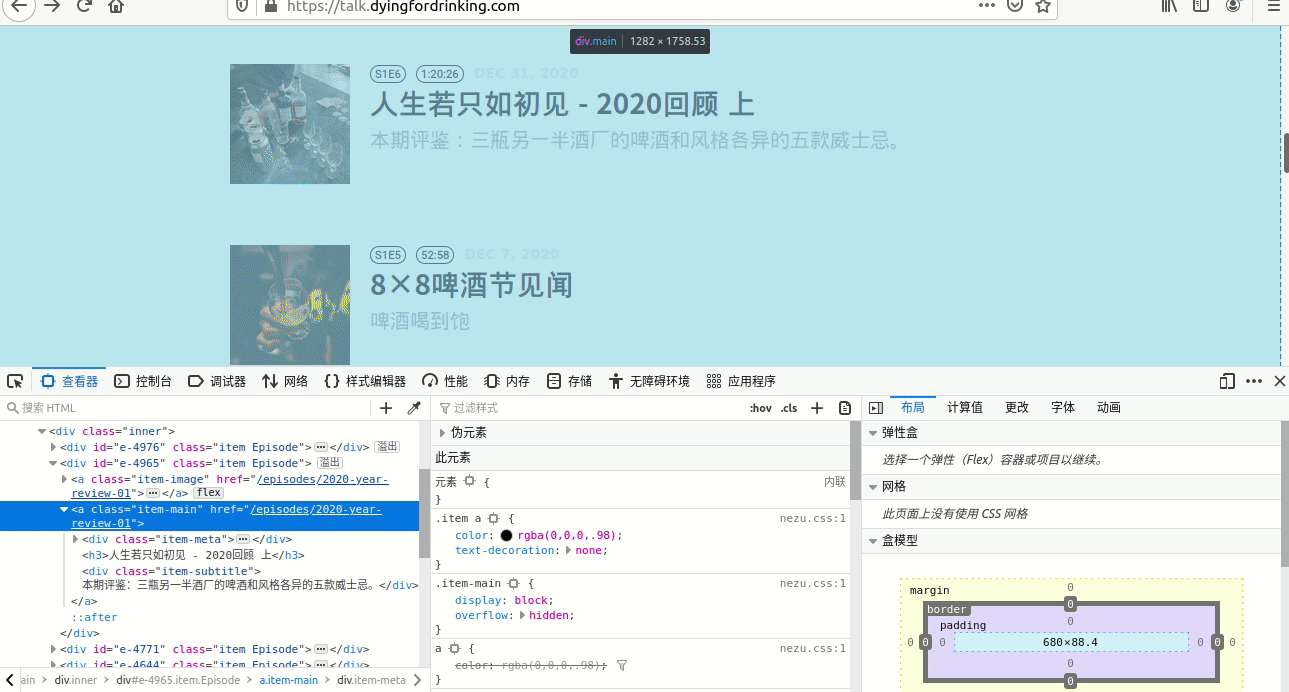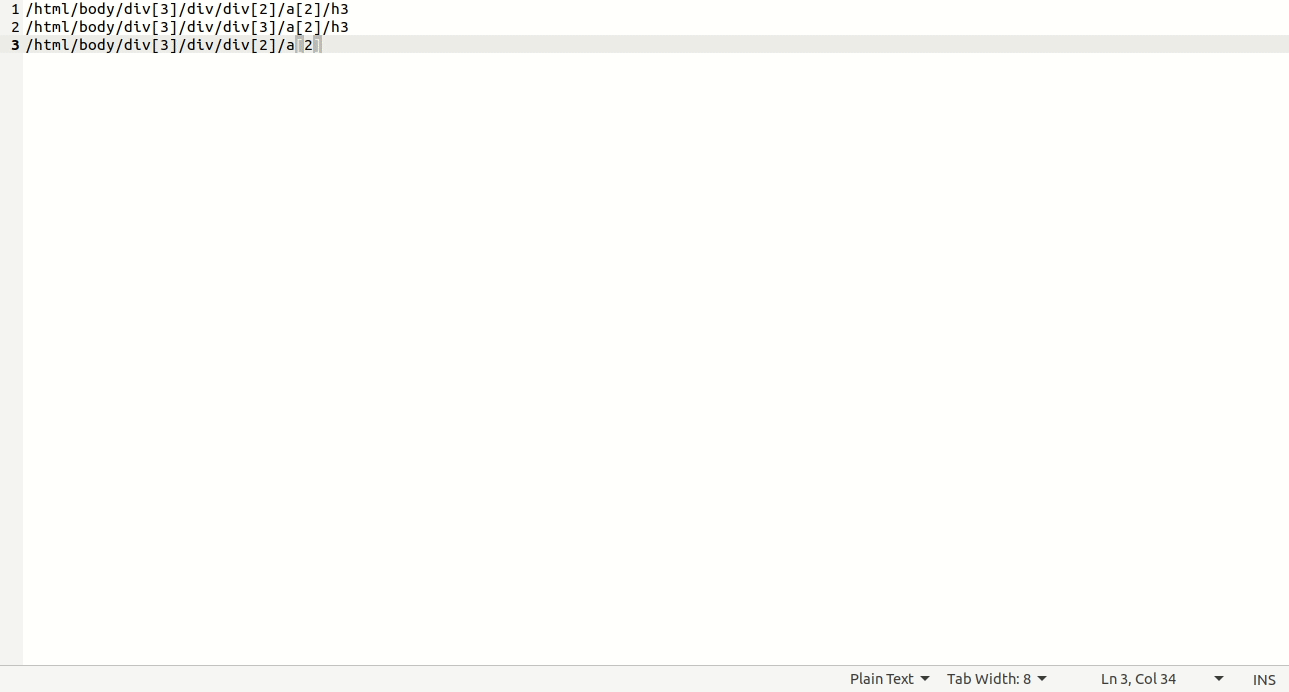
图3
从截图中可以看到,此时的链接是“/html/body/div[3]/div/div[2]/a[2]”, 此时可以像2.6一样,直接取值为“/html/body/div[3]/div/div/a[2]”,注意前面加粗的[2]已经没了, 也可以使用“//div[3]/div/div/a[2]”,但此处用的是”//h3/ancestor::a”,其中ancestor是表示祖先, 可以是父亲、爷爷,此处//h3标题往上查,仅有一个a,就是a[2],因此我们可以直接用ancestor::a, 注意此处的a表示这个元素是一个超级链接元素。
再注意截图中有一个“href=”/episodes/2020-year-review-01””,这个表示这个超级链接没有带网站本 身的网址“https://talk.dyingfordrinking.com/” ,所以后面“条目是否添加base url”要添加上这个网址, 具体往后看,还会细说。
2.9 网站是否更新(一般就是文档类网站不更新)
此处添加这个网站就是为了跟踪网站首页新增了什么条目,所以要选择“是”
2.10 条目是否有时间信息
一般需要更新的网站都会有时间信息,不过如果自用,对时间信息又不是很在意,那可以选“否”,如果在意就要选“是”
选了“是”之后,接着就会在下面增加一个提示框,需要输入“条目时间的xpath_css”
2.11 条目时间的xpath_css
整个过程见图4。
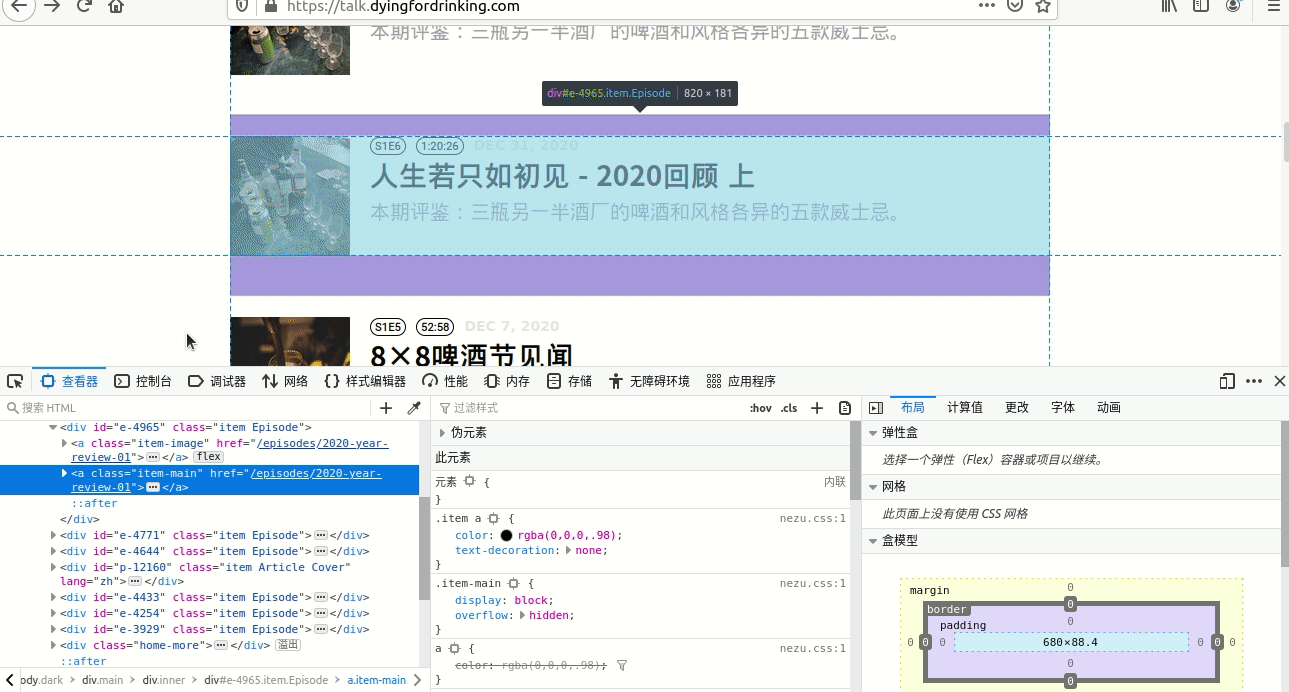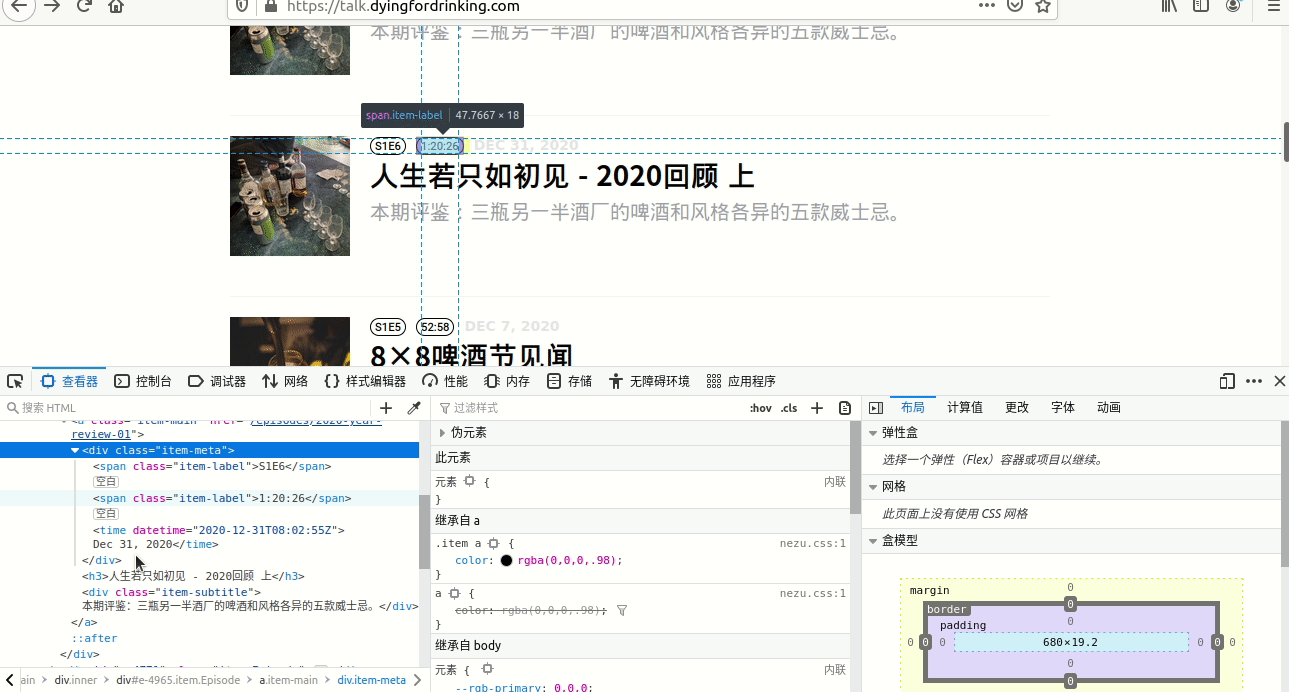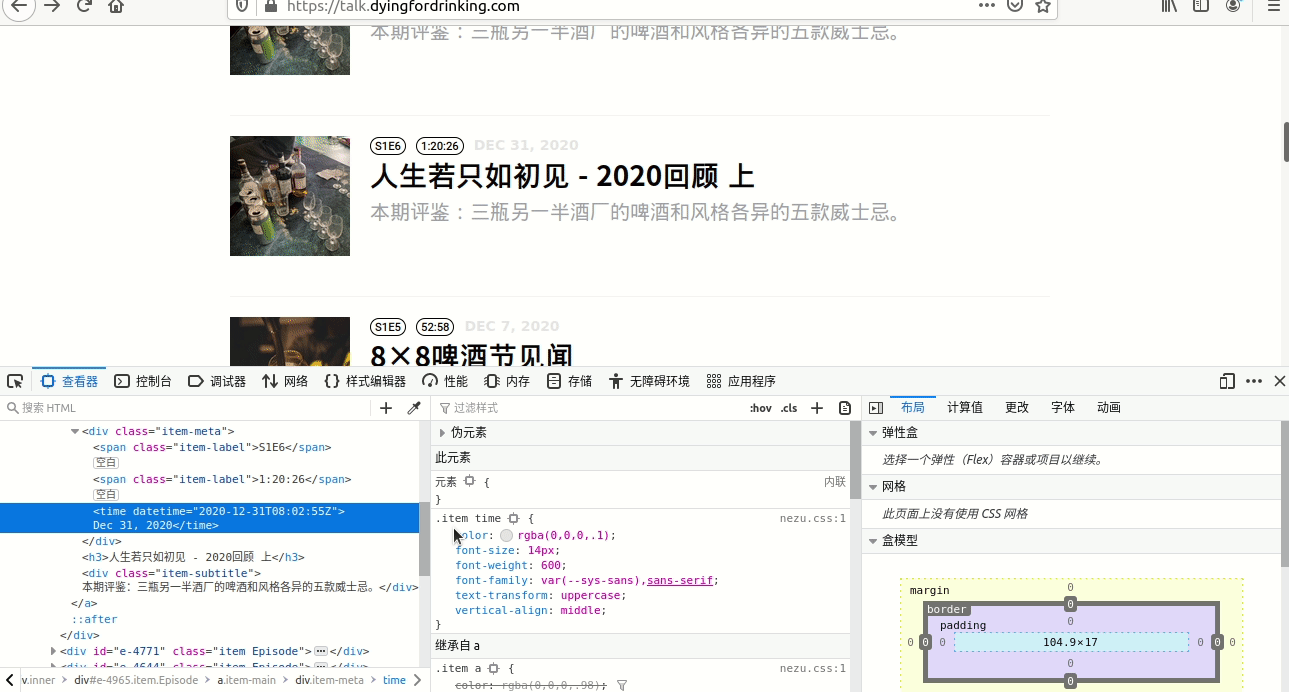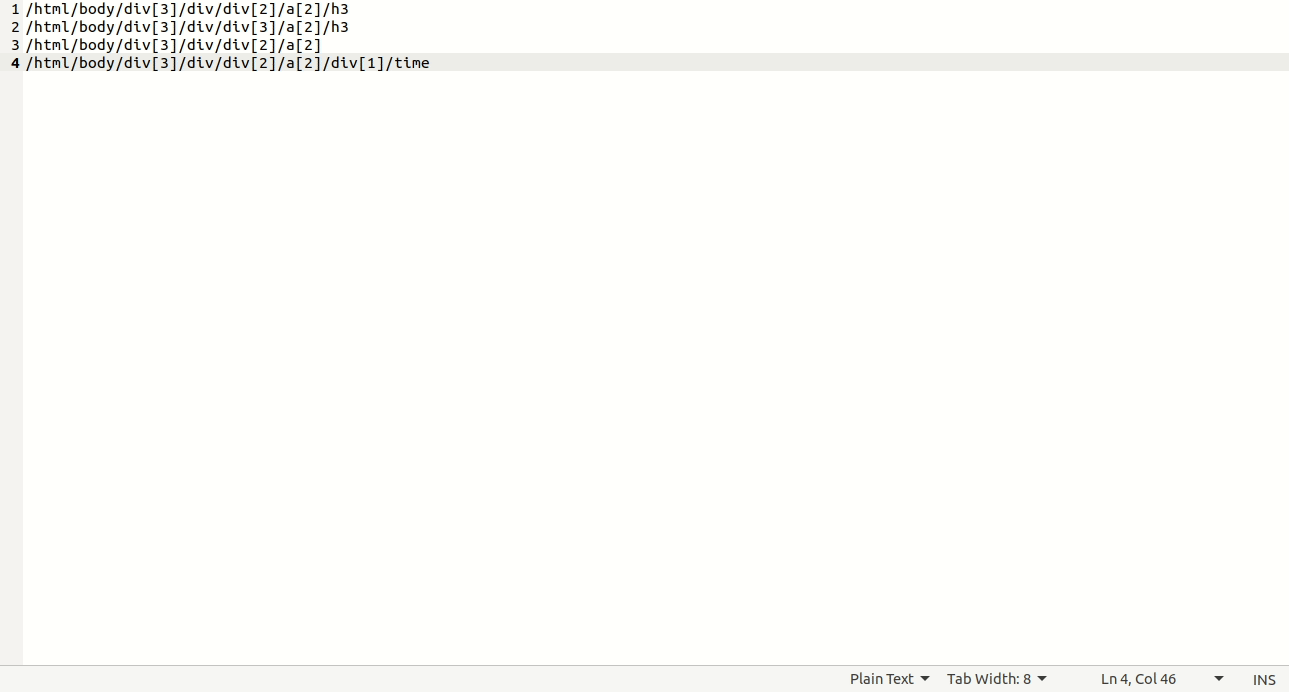
图4
如图中所示,最后从“/html/body/div[3]/div/div[2]/a[2]/div[1]/time”选择 了“//time”,因为仔细观察,仅有这些条目带有time这个节点,其他都没有,所以直接用了//time。
2.12 条目是否添加base url
这个和2.7条相关,2.7条说了我们最后得到的超级链接只是“/episodes/2020-year-review-01”, 无法直接从“翻一会”打开“/episodes/2020-year-review-01”。
因为如果一个网站没有http开头的网址,只有部分链接,那默认的超级链接就是该网址+超级链接, 因此从“翻一会”打开“/episodes/2020-year-review-01”,其实打开的 是“https://fanyihui.net/episodes/2020-year-review-01” ,但这个网址不存在,我们需要打开的是 “https://talk.dyingfordrinking.com/episodes/2020-year-review-01”。
因此我们需要添加条目的base_url,此处就 是“https://talk.dyingfordrinking.com”。
2.13 网站名称
正常就是源网站的名称,此处就是“推杯唤斩”。
2.14 网站标签(最多3个标签)
这个主要是对这个网站进行分类,比如这个网站是个“播客”,所以可以添加“播客”这个标签, 然后这个网站还是谈论酒的,所以也可以算到“饮食男女”标签里。
如果一个标签是绿色的,表示这个标签是所有人都能看到的公用标签,如果是灰色的, 那就是灰色标签,如果有必要,再公开这个网站时,“翻一会”觉得该标签下可以添加不少网站, 那就会把这个标签提升为“绿色”。
这个标签一个网站最多能添加3个。
2.15 网站 / 网页简介
这个主要是对网站的一个简介,如果自己用,那随便写不写都行,如果是要公开给大家订阅的, 那就得好好写写了,如果是申请公开的网站,有必要“翻一会”会主动修改此部分内容。
比如此处直接写“一个播客”就行。
2.16 测试
前面都填好了之后,点击“测试”按钮,等一会,如果各项填的都没有问题,那基本就会得到图5这个截图了。

图5
图中的时间是时间戳的格式,不影响使用,回头修改为正常人类可读的格式吧。
2.17 保存
如果觉得2.15得到结果就是自己想要的,那直接点保存就行了。
这就算完了。
3.添加v2ex网站一个单一的主题
v2ex本身提供rss,但是某一个单一主题的回复是没有rss,那如果希望自己发在v2ex的主题有回复了能立马知道, 一个办法是一直开着v2ex,另一个办法就是将这个主题添加到“翻一会”, 这样自己所有想收到的通知都可以添加到“翻一会”,就可以集中起来看了。
将这个主题添加到“翻一会”,具体步骤如下,其中很多步骤与前面“2.添加“推杯唤斩”这个播客”相同的, 此处就略说了。
3.1 打开“添加阅读源”
与前面一样,登录后点击主页右上角的“添加阅读源“就可以了。
3.2 网站地址
这个一般是整个网站的地址,但此处是想要关注的主题的地址, 比如v2ex上的这个主题“https://v2ex.com/t/741238” ,这个是关于“翻一会”的。
此处就选择“https://v2ex.com/t/741238”。
3.3 是否单页
这个都选择否。
3.4 是否公开
由于是自用,选择否。
3.5 网站源地址
和网站地址相同,都是“https://v2ex.com/t/741238”
3.6 网站源类型
选择html
3.7 条目entry title的xpath css
这个网页上其实只有回复,没有题目,所以我此处就选了每一个回复作为标题, 这次我们换一个浏览器,用chromium浏览器,基本操作都差不多,具体见截图6。

图6
3.8 条目链接的entry link的xpath_css
这个网页正好为每个回复生成了一个网址,比如第21条回复, 网址就是“https://v2ex.com/t/741238#reply21” ,此时选择的这条回复是第8条回复, 所以要找到“8”这个数字的xpath,具体见图7。
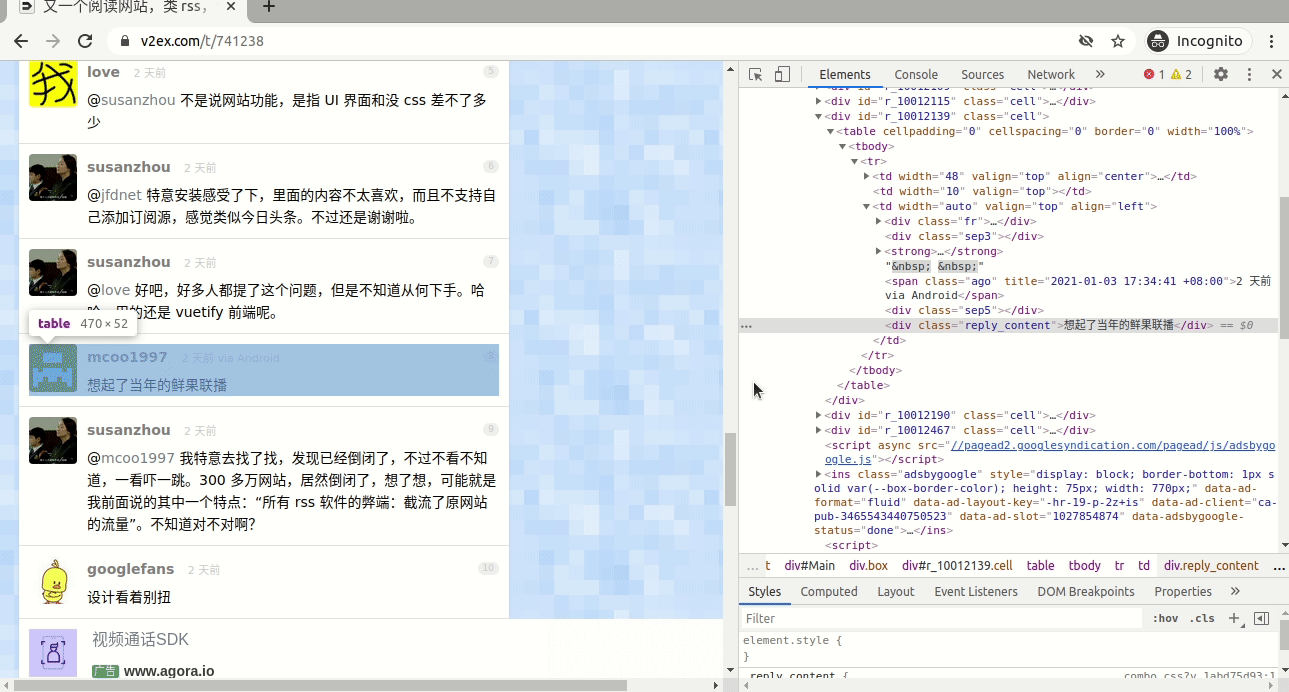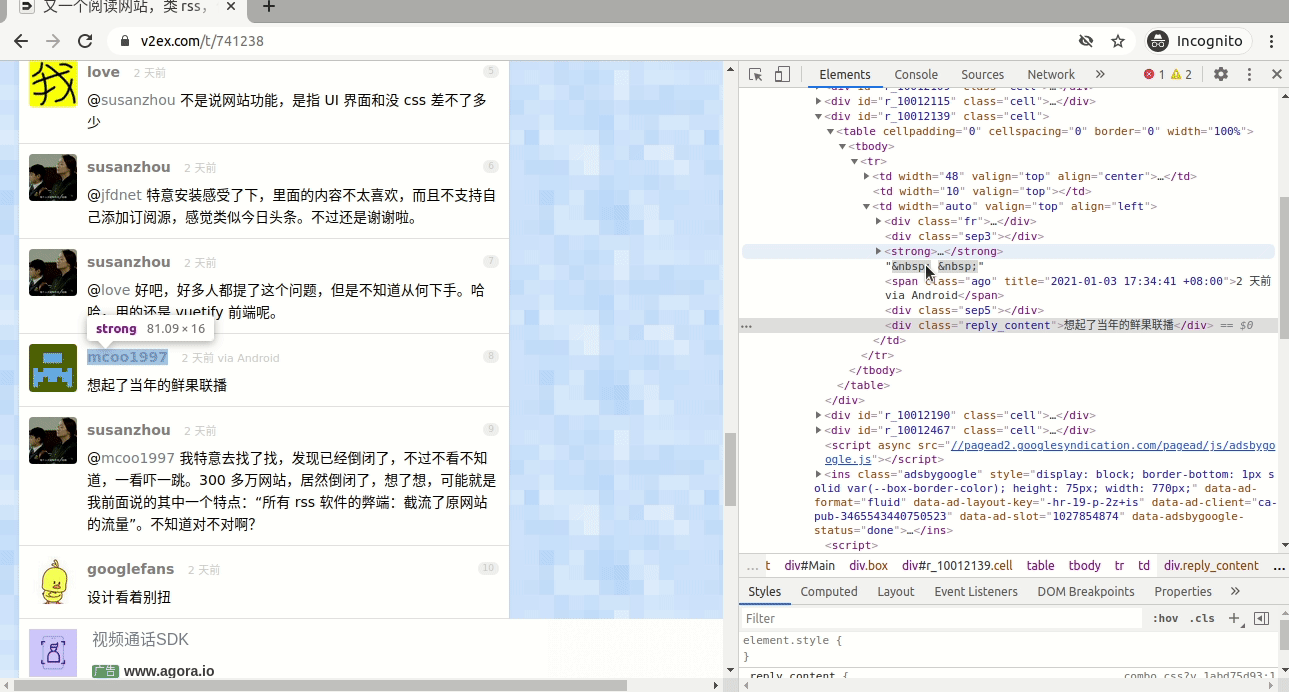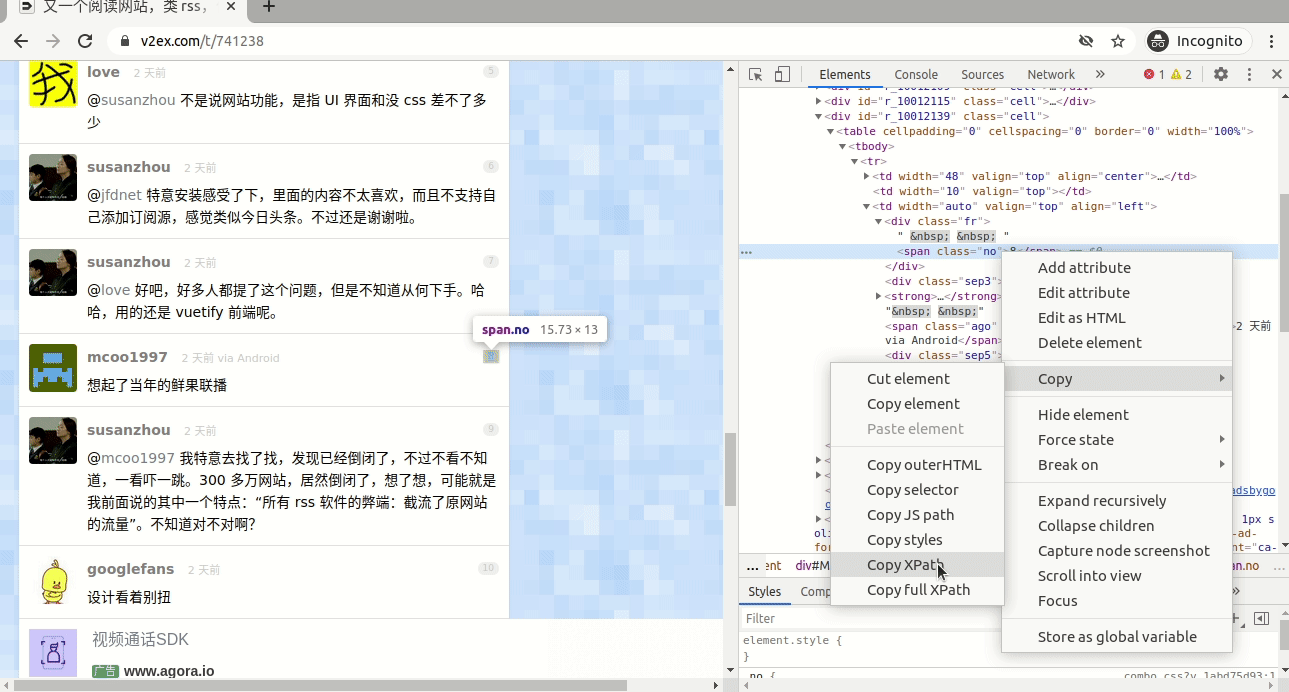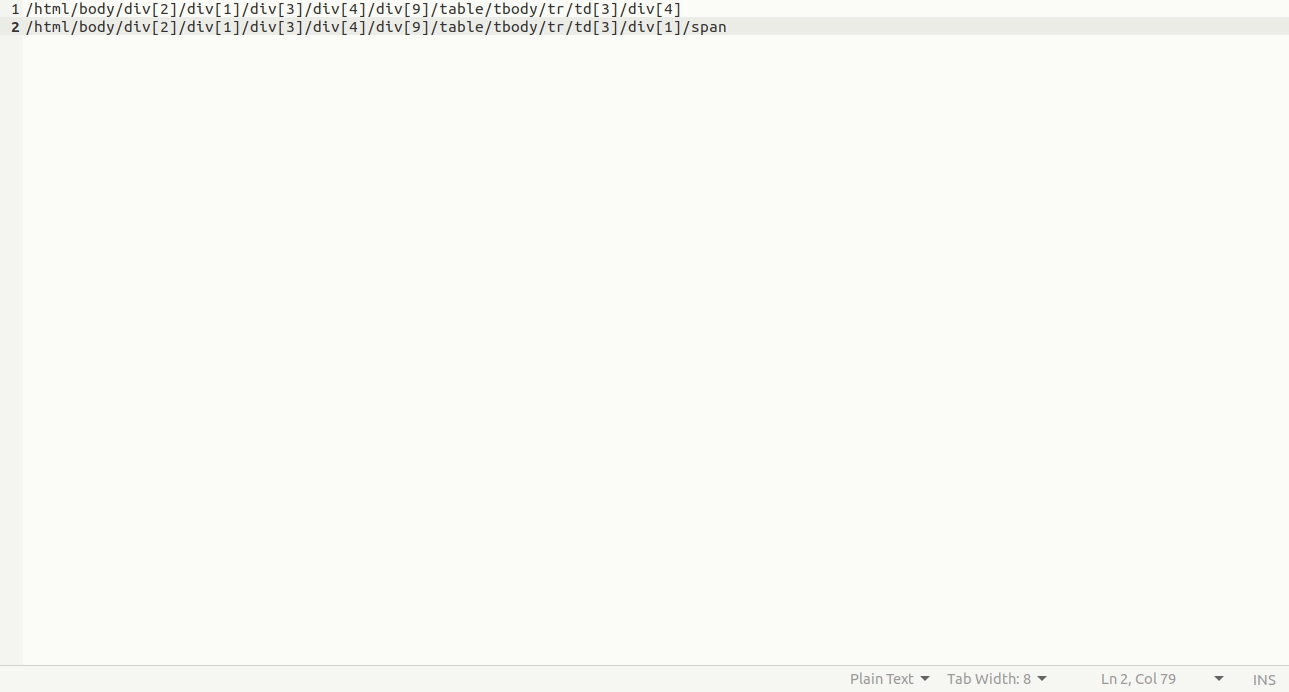
图7
注意到截图中有一个“class=”no””,所以此处我们选的就是“//span[@class=”no”]”。
3.9 网站是否更新(一般就是文档类网站不更新)
此处选择“是”
3.10 条目是否有时间信息
由于仅仅是自用,所以不选取时间信息,此处就选“否”。
3.11 条目是否添加base url
此处当然需要添加base_url,将base_url加前面得到的“8”这个字,就需要组成这个 链接:“https://v2ex.com/t/741238#reply8”
所以,此处填的就是“https://v2ex.com/t/741238#reply” ,就是后面8这个数字没有。
3.12 网站名称
此处填的是“v2ex-又一个阅读网站,类 rss,但不是 rss”,网站名称每个用户只能填一个值, 如果两个值相同,则不能添加。
3.13 网站标签(最多3个标签)
选择“自用”
3.14 网站 / 网页简介
随便填一下,比如“v2ex-又一个阅读网站,类 rss,但不是 rss”。
3.15 测试
填完了,选择“测试”,如果如截图8所示,那就是所要的结果。
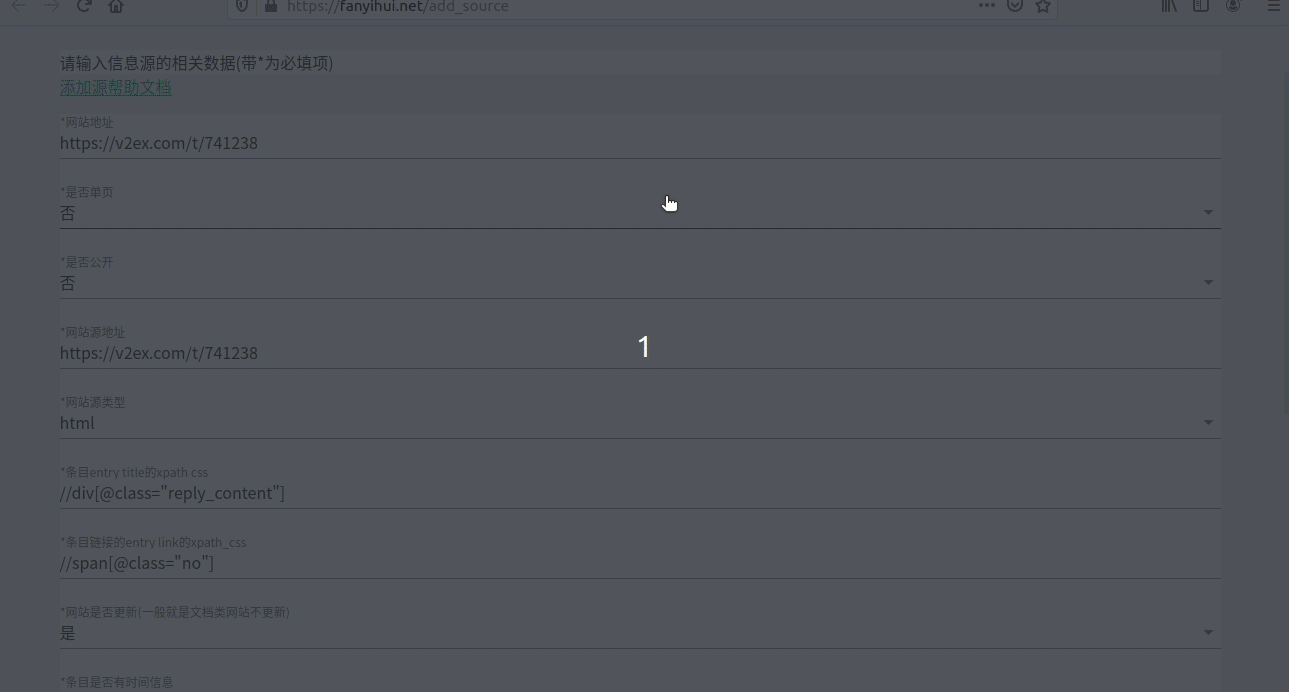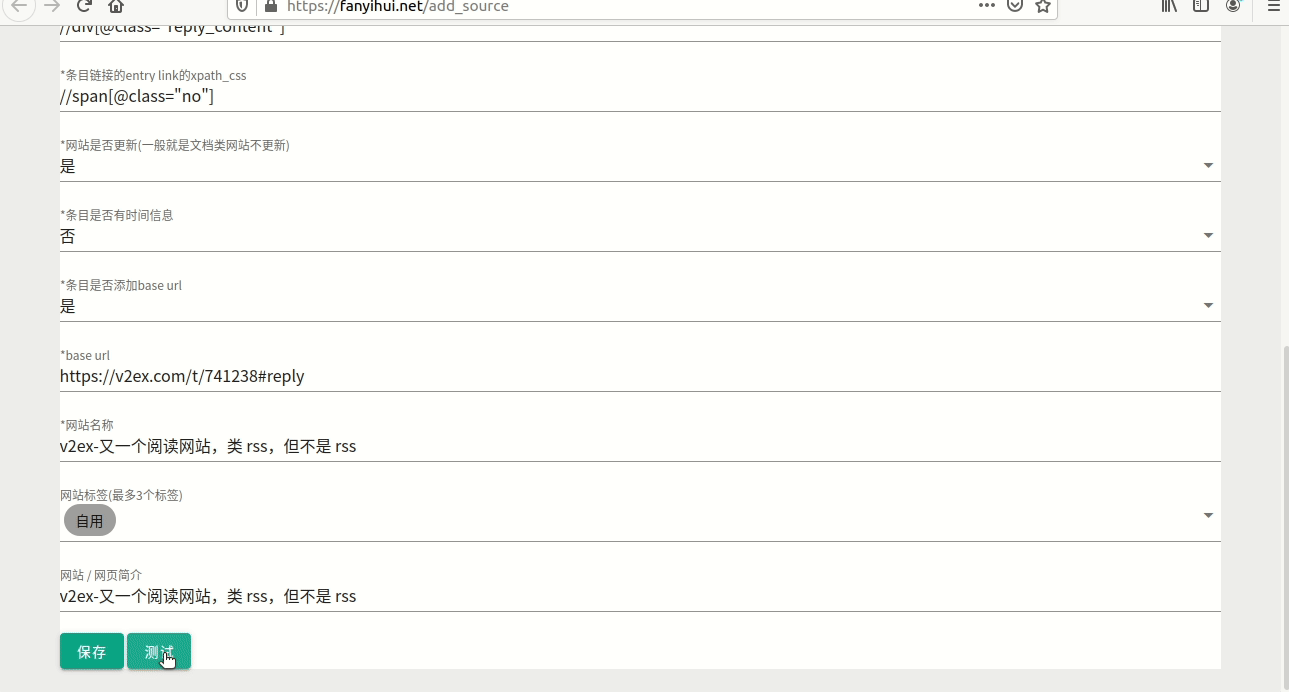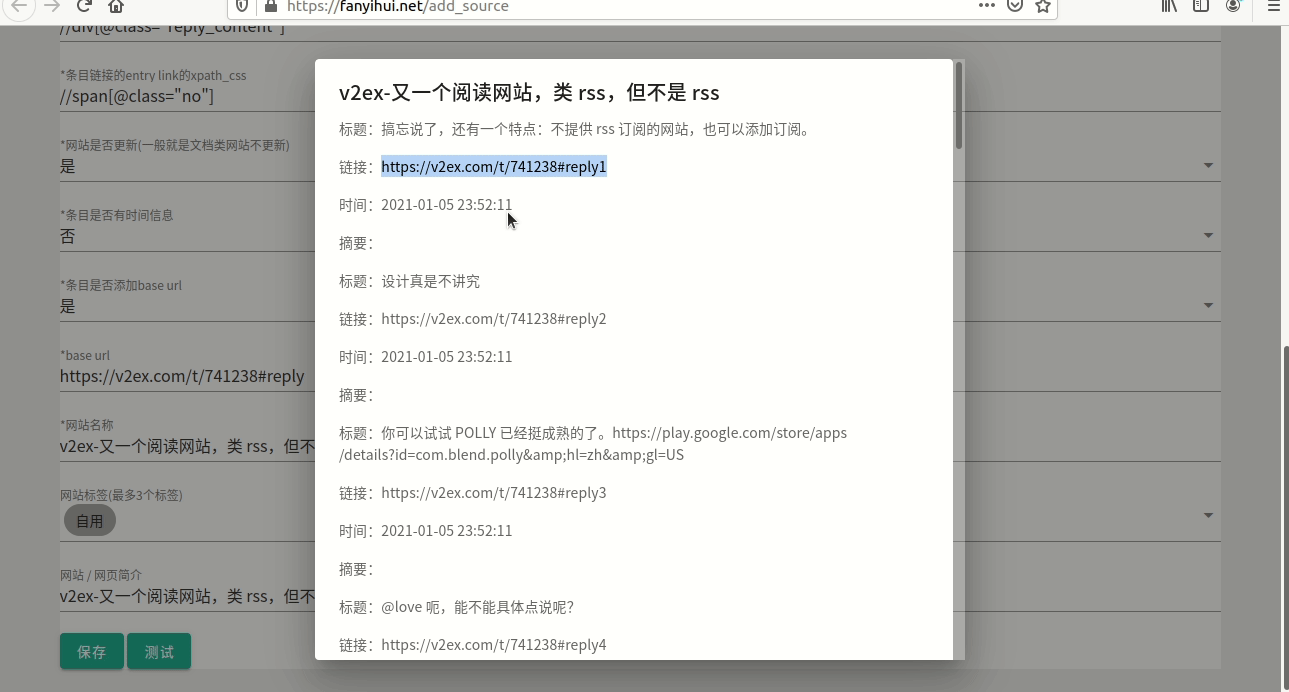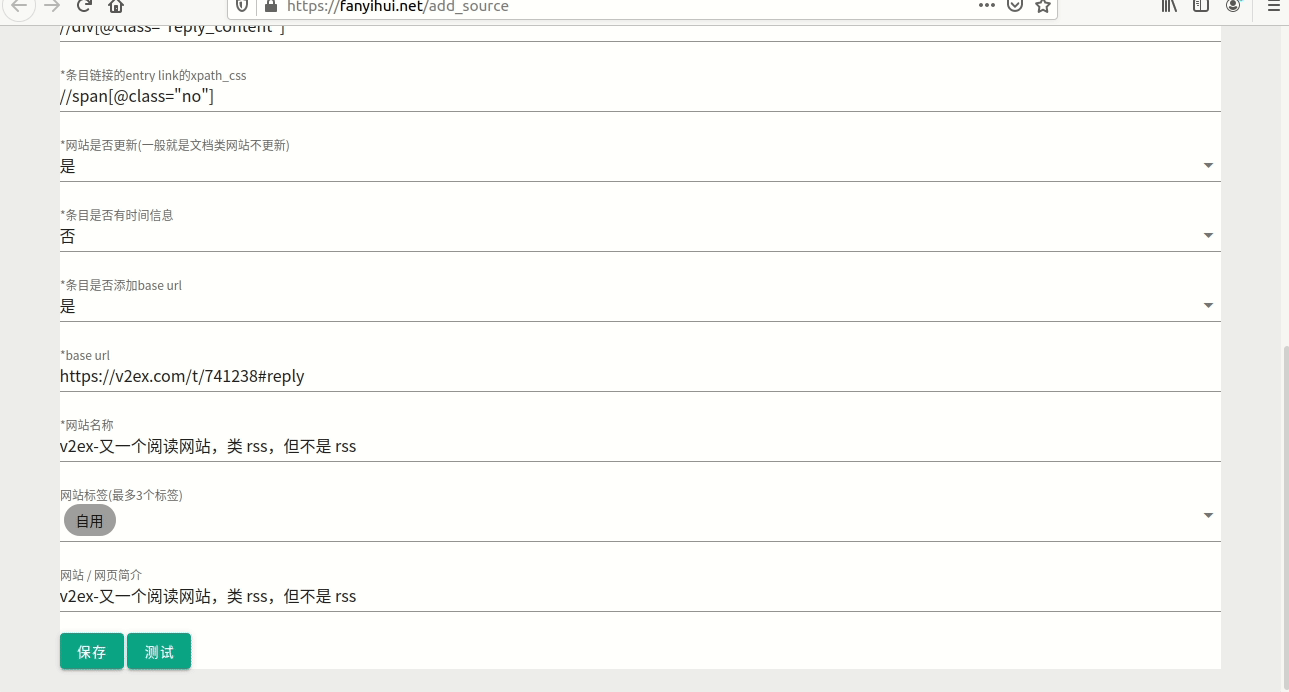
图8
3.16 保存
接着“保存”就好。
以上,两个例子,大家可以举一反三,还可以看看前面已经推荐过的 xpath教程。
欢迎使用,欢迎反馈,可以发邮件:contact@fanyihui.net,也可以联系微信:fanyihui-support。